Scalding on Hadoop in Practice
2014-09-11
##About Scalding is a open source library that lets you write MapReduce programs that look like native Scala collection transformations and execute them on Hadoop. It’s launched and widely used in Twitter. The goal is to design big data systems that are as powerful & seamless as those for small data.
##Overview For example, a wordcounting aggregation in pure Scala might look like this:
def wordCount(source: Iterable[String], store: MutableMap[String, Long]) =
source
.flatMap { line => line.split("""\s+""")
.map(_ -> 1L)}
.foreach { case (k, v) => store.update(k, store.get(k) + v) }
However, counting words in Scalding looks like this:
TextLine( args("input") )
.flatMap('line -> 'word) { line : String => line.split("""\s+""") }
.groupBy('word) { _.size }
.write( Tsv( args("output") ) )
The logic is exactly the same and the code is almost the same. The main difference is that you can execute the Scalding program in batch mode on hadoop. The API is inspired by spark, in which counting words looks like:
spark.textFile("hdfs://...")
.flatMap(line => line.split("""\s+""")).map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile("hdfs://...")
##API��
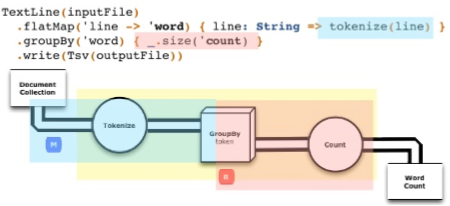
You can be effective within hours by just learning a few simple ideas
- TextLine/Tsv(Field rules)
- map/flatmap
- filter
- groupBy
- reduce/foldLeft/size/sum
- limit/debug
Everything above takes a function as an argument.
##Get Started https://github.com/twitter/scalding#scalding
https://github.com/twitter/scalding/wiki/Getting-Started
https://github.com/willf/scalding_cookbook
##Input Source and named fields Scalding can handle both HDFS data and local data (useful for test and debug). There are a couple of useful input sources to get hands on.
TextLine(filename)
Let’s start with the simplest one.
TextLine(args("input"))
TextLine("~/data/input.txt")
For each line, generate a tuple containing two named fields, ‘line and ‘offset.
###Csv and Tsv Used in both local and HDFS mode, you can specify the name of the field for clearity or make use of the header to do the nameing.
Tsv(args("input"), ('userid, 'computerguid, 'event, 'json)).read
###WritableSequenceFile Used to read Sequence files in HDFS. Parse each line to (Long, String)
WritableSequenceFile(args("input"), ('serialNo, 'data))
###IterableSource Create a pipe form a scala Iterable. Note that IterableSource can only be used in job mode, that’s to say, It couldn’t be used in REPL directly.
IterableSource(List(4,8,15,16,23,42), 'foo)
###NullSource
Scalding got some concealed optimizations. One is that codes with only side effect (transforming a pipe while not writing to anywhere) with never be executed.
For instance, if you only want to print a few lines of a pipe
Csv(input).limit(10).debug
you might get nothing and wondering if you did anything wrong in elsewhere. In effect, you should write
Csv(input).limit(10).debug.write(NullSource)
to make sure your side effect would take effect.
##Troubleshooting
- We don’t recommend using scalding/scripts/scald.rb in production. scald.rb is good for learning. While you might encounter many miraculous bugs if you insist using it in development. Be careful with “scald.rb clean”.
- Scala spreadSheet in IDE is a much better tool than REPL for trial and error.
- IterableSource is especially useful for unit testing. While it can only be used in Job mode, which means that it’s not ready to use in REPL as spark do.
- Side effects might never have the chance to be executed due to code optimization. A NullSource is useful if you wish to create a pipe for only its side effects (e.g., printing out some debugging information). For example, although defining a pipe as Csv(“foo.csv”).debug without a sink will create a java.util.NoSuchElementException, adding a write to a NullSource will work fine: Csv(“foo.csv”).debug.write(NullSource).
- We use WritableSequenceFile to read Sequence files on HDFS, which translates each line in the file to (Long, String)
- readAtSubmitter[Map(String,String)] won’t translate the line to a Map(String,String) as the compiler supposed.
##FAQ Q) What happens if I get OutOfMemoryErrors when running “sbt assembly”?
A) Create ~/.sbtconfig with these options: SBT_OPTS=”XX:+UseConcMarkSweepGC XX:+CMSClassUnloadingEnabled XX:PermSize=256M XX:MaxPermSize=512M”
Q) What happens if I get something like “java.lang.UnsupportedClassVersionError: XXX Unsupported major.minor version 51.0”
A) I once encounter this error, which might be caused by Java version mismatching, when a Java Class is introduced into Scala project. Edit PROJECTHOME/build.sbt and add javacOptions ++= Seq(“source”, “1.6”, “target”, “1.6”)
Q) Missing data
A) Pass the option tool.partialok to your job
Q) Read a single reduced value from a pipe
A) Job.next & Source.toIterator
Q) Cases classes wouldn’t work
A) Define it outside of your Job
Q) Hadoop jobConf
A) pass parameters to hadoop job
hadoop jar myjar \ com.twitter.scalding.Tool \
-D mapred.output.compress=false \
-D mapred.child.java.opts=-Xmx2048m \
-D mapred.reduce.tasks=20 \ com.class.myclass \
--hdfs \
--input $input \
--output $output
Q) What if I got hadoop jobconf oversize problem?
A) You might have defined a local scala collection over the size of 5M.
It won’t go for long to increase the limit in hadoop configuration. Try write the collection to HDFS or Using the distributed cache. Note that the LookupService is highly domain specific and would not fit into other projects. It is only an example of what essentially is a custom index that is implemented as a binary file (a database, more or less).
The DistributedCacheFile is a thin wrapper around functionality provided in hadoop that allows you to register files that should be present on the local disk on each of your mappers (and I believe reducers as well). You tell hadoop “I need file X on the mappers at location ./x” and hadoop takes care of copying it and providing you access at the name you specify. That’s it. The DistributedCacheFile takes care of registering a unique name for you and hiding the details so you can avoid collisions and focus on solving the problem at hand.What you put in that file is up to you. If you want a general purpose index, you would either need to implement your own, or somewhat more sensibly, you could use one of a number of key-value stores available for java.
So the workflow looks like:
- Generate a custom distributable (embedded) index
- copy that index into HDFS in a known location
- Register that location using DistributedCacheFile as part of your job
- Access the path at map/reduce time and load the index
##My Blog Series in Chinese Scalding初探之一:基于Scala的Hadoop利器
转载请注明出处:Scalding on Hadoop in Practice